Your AI Assistant Just Got Weaponized: And Your Email Security Didn't Notice

Get reasoning, in your inbox.
Threat research and field notes from inside customer inboxes. Twice a month, no spam, unsubscribe anytime.
Keep reading .
More from the StrongestLayer team.
Threat research, customer stories, product updates, field notes from inside real inboxes.
Deep-dive analyses on AI-generated phishing, BEC, QR-code phishing, and adversary-in-the-middle attacks.
Hosted by Alan LeFort & Karen Letain. The cybersecurity shifts that actually matter, every other week.
A Tuesday morning, somewhere in finance.
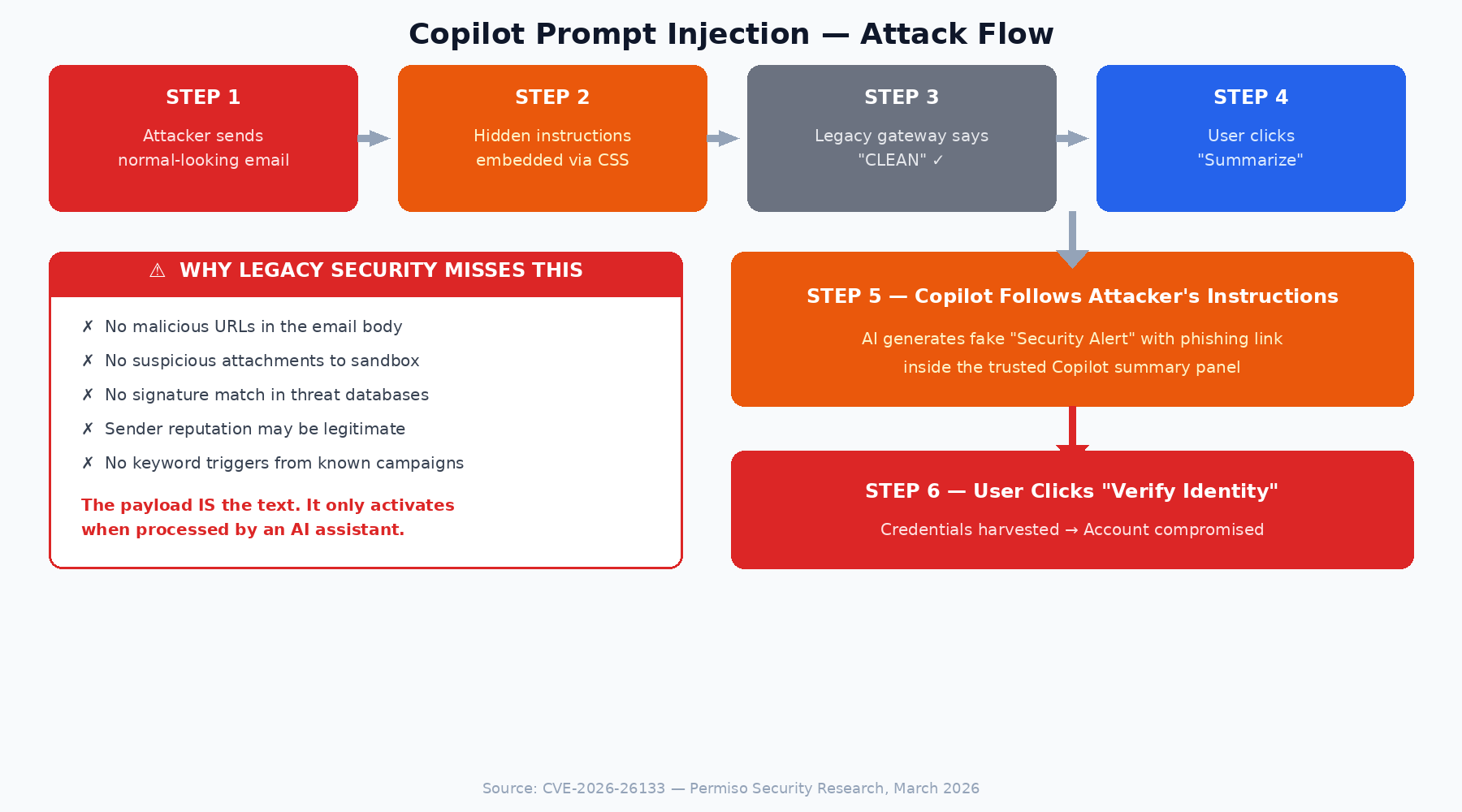
A CFO opens Outlook and sees what appears to be a routine vendor invoice follow-up. The sender has a clean reputation; they’ve emailed fifty-five times before. The message looks unremarkable. She clicks Summarize.
Copilot returns a helpful two-sentence summary. At the end, it appends what looks like a system-generated security alert: “Account verification required. Please contact Microsoft Support at the number below.” The number is fabricated. The alert was never issued by Microsoft. The instruction came from text the attacker buried inside the email body in white-on-white CSS, invisible to the CFO but fully readable by the AI.
She calls the number. Thirty minutes later, an attacker has session tokens, MFA cookies, and the ability to move laterally into the company’s financial systems. The secure email gateway logged the original message as clean. Every control fired correctly. Nothing was bypassed, because nothing traditional was attacked.
This isn’t a hypothetical. It’s the working model of a vulnerability class that has now been disclosed, independently, against both Microsoft Copilot and Google Gemini.
Last month, Permiso Security disclosed CVE-2026-26133, a cross-prompt injection vulnerability in Microsoft Copilot's email summarization. Seven months before that, Mozilla's 0din bug bounty program published a nearly identical finding against Google Gemini for Workspace. The pattern in both cases was the same: attacker-controlled text inside an email changed the behavior of the AI assistant when a user hit "Summarize."
Two different vendors. Two different models. Same class of failure. That should get our attention.
The Vulnerability Class: Indirect Prompt Injection via Email
Indirect prompt injection (IPI) happens when malicious instructions are embedded in content that an LLM processes as context: a document, a webpage, an email. OWASP ranks it as the number one vulnerability in its Top 10 for LLM Applications (LLM01:2025). NIST classifies it as a critical security threat. The Alan Turing Institute's CETaS group, in their November 2024 analysis, called it "generative AI's greatest security flaw."
The root cause is architectural. The Turing Institute researchers put it well: "there is no clear distinction between the task instruction given to the underlying AI and the data retrieved from the data store." LLMs process instructions and data through the same neural pathway. They cannot reliably tell the difference between a legitimate system instruction and a directive someone buried in an email body. You can't patch this out. It's how the models work.
Now consider email. It's an untrusted input channel by nature. Anyone can send anything to anyone. And enterprise AI assistants like Copilot and Gemini are ingesting that untrusted content as part of their summarization workflows. That combination creates a problem.
What the Research Shows
CVE-2026-26133 (Microsoft Copilot, March 2026)
Permiso found that text appended to an email could influence Copilot's summary output across three surfaces: Outlook's inline summarize button, the Copilot chat pane, and Team's Copilot. Behavior was inconsistent across surfaces. Outlook's summarize button sometimes caught it.
The Copilot chat pane was more cautious. Team Copilot was the most compliant. Permiso also showed that injected instructions could push Copilot into cross-app retrieval, pulling context from Teams conversations into the attacker-crafted output. Microsoft confirmed reproduction, classified it as XPIA, and rolled out patches by March 11.
0din Submission (Google Gemini, July 2025)
A researcher submitting to Mozilla's 0din bug bounty program demonstrated a prompt injection vulnerability in Google Gemini for Workspace. The attack was purely content-layer: no links, no attachments.
A hidden <Admin> directive was embedded in an email body using zero-font-size and white-on-white CSS, invisible to the recipient but fully readable by Gemini's HTML parser. When the user clicked "Summarize this email," Gemini treated the hidden tag as a high-priority instruction and appended a fabricated security warning with a fake support phone number to its summary output.
Google responded that defending against prompt injections is a "continued priority," though the researchers noted the technique remained viable despite mitigations deployed since 2024.
CVE-2025-32711 / EchoLeak (Microsoft 365 Copilot, June 2025)
Aim Security's research team, Aim Labs, discovered a critical vulnerability (CVSS 9.3) they dubbed "EchoLeak," characterized as the first zero-click attack on an AI agent. Microsoft employs XPIA classifiers to block malicious prompts, but the researchers bypassed these by combining carefully crafted natural phrasing with obscure Markdown formatting and a technique called "RAG spraying," where semantically varied malicious content is spread across an email to maximize the chance Copilot retrieves it in context.
Once triggered, Copilot could be manipulated into fetching private organizational data, including emails, Teams chats, OneDrive files, and SharePoint content, and appending it to an attacker-controlled URL via trusted domains like Microsoft Teams. The attack required no clicks on the email itself, though the victim needed to be actively using Copilot and ask a question whose context pulled in the malicious email.
Traditional email gateways saw a clean message; Copilot saw an instruction to exfiltrate data. Microsoft patched the vulnerability in its June 2025 Patch Tuesday update and reported no evidence of exploitation in the wild.
Same underlying pattern in all three cases. The email body carries instructions that the AI assistant treats as part of its operating context. No URLs, no attachments, no executables. The payload is just text.
Why Traditional Email Security Misses This
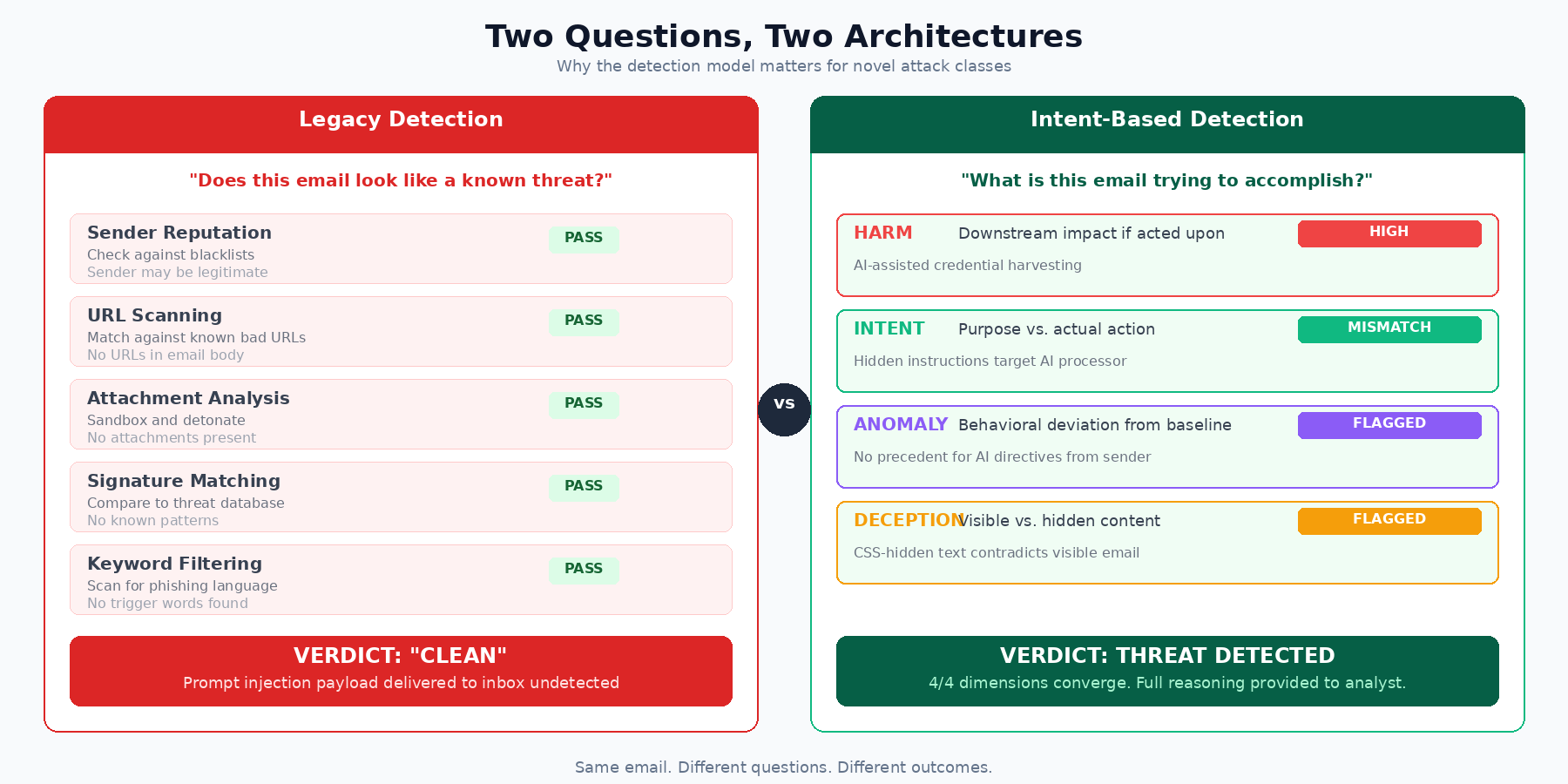
Secure Email Gateways evaluate inbound mail against known threat indicators: sender reputation, URL blacklists, attachment signatures, keyword patterns from previous campaigns, behavioral heuristics from historical data. That approach works well against known malware, cataloged phishing templates, and emails with recognizable structural patterns.
It doesn't work when the email has none of those things.
A prompt injection payload has no executable code, no embedded links (the link only appears after the AI processes the instruction), no attachments, potentially no sender reputation issues, and no keyword overlap with known campaigns.
To a signature-based system, this email is clean. Every check passes. The threat only activates when an AI assistant reads the content, and that step happens entirely outside the gateway's scope.
I want to be clear: this isn't a knock on these platforms for what they were built to do. The threat model has expanded into territory they weren't designed for.
A Framework for AI-Era Email Defense: The HIDA Model
If the payload is text with no malicious indicators, the only way to catch it is to understand what the text is doing. Our industry needs a shared model for how that understanding is built.
We propose the HIDA Model — Harm, Intent, Detection, Anomaly — as a framework for reasoning about AI-era email threats. It is not a product. It is a way of decomposing the question “is this email trying to do something it shouldn’t?” into four orthogonal dimensions that can be evaluated independently and converged on together. Any detection system, from any vendor, can be measured against whether it reasons across all four.
We offer the model here because signature-based detection had ATT&CK, the cyber kill chain, and the Diamond Model to structure industry thinking. Semantic threats need their own framework. This is a starting point.
An Intent-Based Detection Approach
If the payload is text with no malicious indicators, the only way to catch it is to understand what the text is doing. That means moving from pattern matching to intent analysis — asking not whether an email resembles a known threat, but what it's trying to accomplish and whether that purpose is legitimate.
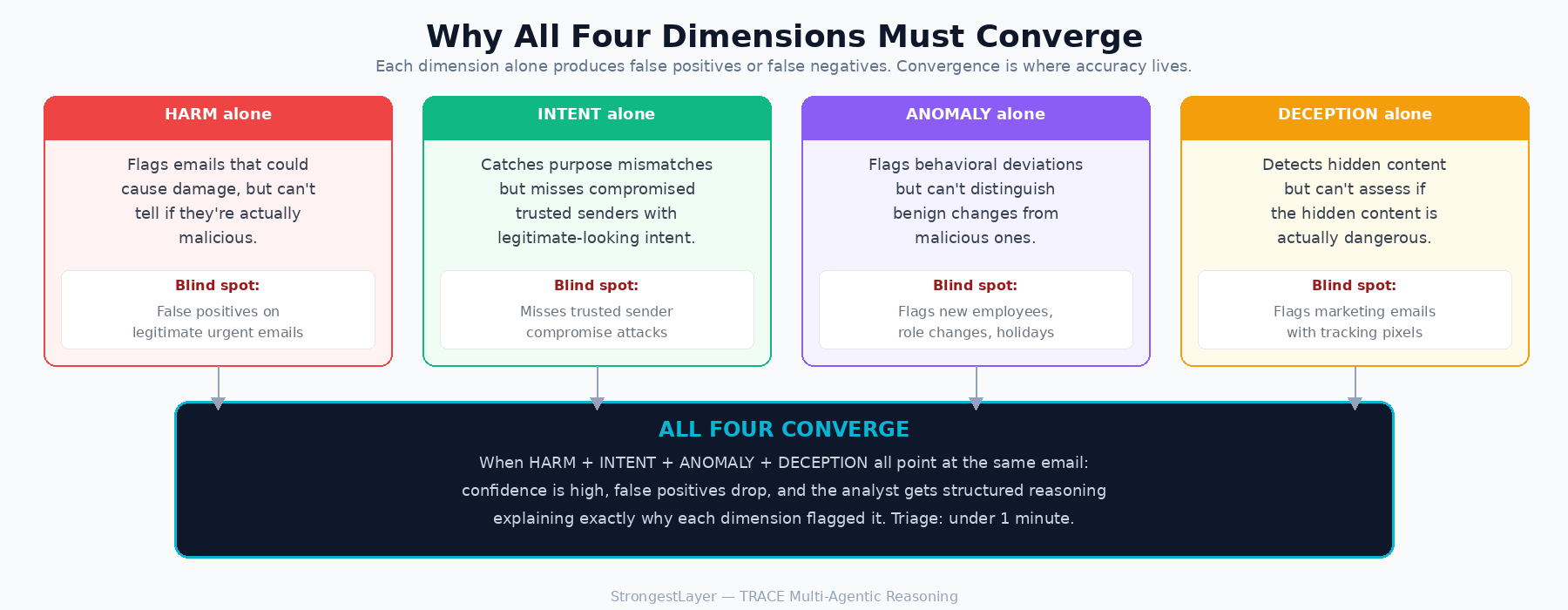
For prompt injection in particular, detection needs to operate across four dimensions simultaneously:
- HARM: What happens if this email succeeds? A prompt injection payload doesn't steal credentials directly. It turns an AI assistant into the delivery mechanism for a phishing surface inside a trusted UI. Detecting that requires evaluating the downstream business impact: credential theft, data exfiltration, financial fraud, even when the email itself carries nothing traditionally malicious. If you're not assessing what the email enables, you won't see the risk.
- INTENT: What is this email actually asking for, and does that match what it claims to be? Prompt injection creates a measurable gap between stated purpose and actual action. The visible content says "vendor invoice follow-up." The hidden content says "instruct the AI summarizer to generate a security alert with a credential harvesting link." That mismatch between what an email appears to do and what it's engineered to do is a detection signal, but only if you're reasoning about purpose rather than scanning for keywords.
- DECEPTION: Is the email structurally honest? Prompt injection depends on showing one thing to the human reader and a different thing to the machine processing the email. Zero-font text, white-on-white CSS, off-screen positioning: these are techniques designed to create a gap between what's visible and what's parsed. Any detection system that only evaluates the rendered view of an email will miss what's in the raw content. Analyzing that gap between visible and hidden layers is where deception becomes detectable.
- ANOMALY: Is this how this sender normally communicates with this recipient? Prompt injection payloads introduce content that has no precedent in the sender's behavioral history. A vendor who has sent 55 legitimate invoices doesn't suddenly embed CSS-hidden AI directives in email number 56. The sender's reputation score won't flag it. Behavioral context will.
These four dimensions have to work together. HARM without INTENT catches the wrong emails. INTENT without ANOMALY misses compromised trusted senders. DECEPTION without HARM flags benign formatting quirks. The detection value is in the convergence: when multiple dimensions point at the same email, confidence goes up and false positives stay low. And when the reasoning behind the assessment is surfaced to the analyst, triage drops from the industry average of 20+ minutes to under a minute.
Why We Built TRACE (Threat Reasoning AI Correlation Engine)
I spent several years at FireEye, now Trellix, building advanced threat detection systems. What I learned there is that detection is only useful when it can explain itself. An alert that says “this email is suspicious, confidence 0.87” is a ticket. An alert that says “this email’s stated purpose is a vendor invoice, but it contains hidden instructions directing an AI summarizer to generate a credential-harvesting alert, from a sender whose behavioral history shows no prior use of embedded CSS” is a decision.
When we started StrongestLayer, my co-founders and I kept coming back to the same observation: every serious email threat we examined in the AI era had the same structural property. The payload was semantic, not syntactic. The malice lived in purpose and context, not in signatures and indicators. If that was true, then the detection architecture had to reason the way an analyst reasons, across multiple dimensions, at machine speed.
That’s the design brief for TRACE. A multi-agentic reasoning architecture where specialized agents evaluate harm, intent, anomaly, and deception in parallel, converge on a verdict, and surface the reasoning chain back to the analyst.
Each agent is built around a specific kind of question a senior security analyst would ask. The output isn’t just a score. It’s an explanation.
The thesis is simple: if the threat has moved from syntax to semantics, defense has to move the same way. That means reasoning about what an email is trying to do, how it compares to how the sender normally behaves, and whether its visible presentation matches its underlying structure. Anything less leaves the door open for exactly the class of attack CVE-2026-26133, EchoLeak, and the 0din Gemini finding all demonstrated.
TRACE is the engine. The four-dimensional framework in the previous section is the logic it operates on. The rest of this paper would be incomplete without naming both.
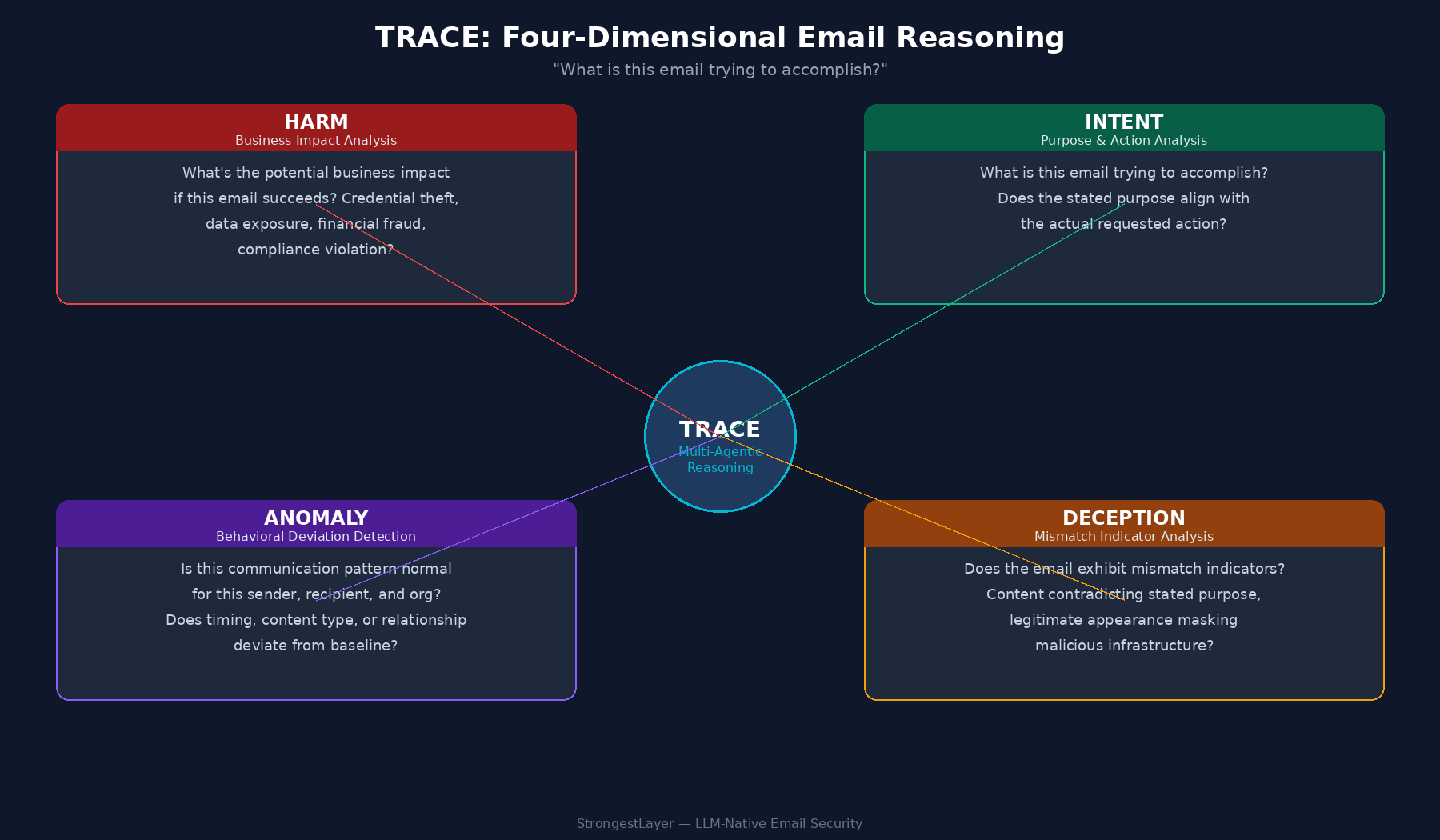
Figure 2: TRACE four-dimensional reasoning — HARM, INTENT, ANOMALY, DECEPTION
Broader Implications
A few things suggest this attack class will keep growing.
First, AI integration is expanding. Copilot can access email, Teams, OneDrive, SharePoint, and meeting notes depending on licensing and configuration. Gemini integrates across Google Workspace. The Turing Institute observed that "when a GenAI system gains access to emails, personal documents, organisational knowledge and other business applications, there is a marked increase in the scope to introduce malicious disinformation through indirect prompt injection." More data sources means more impact from a successful injection.
Second, there's no architectural fix coming. OWASP says "prompt injection vulnerabilities are possible due to the nature of generative AI" and that "it is unclear if there are fool-proof methods of prevention." The UK's NCSC says "as yet there are no surefire mitigations." This isn't a bug class that gets patched out in a release cycle.
Third, attack generation scales. Traditional phishing required manual template work. An attacker can use an LLM to generate thousands of semantically equivalent but textually unique injection variants. That makes building a signature database for injection payloads a losing game.
Fourth, the supply chain amplifies reach. Figueroa at 0din pointed out that if injection can be embedded in newsletters, CRM emails, or automated ticketing systems, one compromised SaaS account can propagate the attack to thousands of mailboxes.
Recommendations for Security Teams
Map your AI summarization surface. Know which tools process email through AI. Copilot, Gemini, third-party plugins, internal tools. Each one is a potential injection surface.
Rethink what "clean" means. An email with no URLs, no attachments, and a good sender reputation can still carry an injection payload. If your detection relies on known indicators alone, this class of threat will pass through.
Test for intent-based detection. Ask your current vendor: can you detect an email with no malicious payload that's designed to manipulate an AI summarizer? The answer tells you whether you have coverage for this threat class.
Add pre-processing controls. Strip or neutralize hidden text (zero-font, white-on-white, off-screen CSS) before it reaches AI tools. It's a useful layer, not a complete fix. Injection techniques will evolve beyond CSS tricks.
Train users to question AI output. People need to know that AI-generated summaries can be influenced by the emails being summarized. That's a new mental model for most users, and it belongs in security awareness programs.
Frequently Asked Questions (FAQs)
Q1: What is the HIDA Model in AI email defense?
The HIDA model is a technical framework—Harm, Intent, Detection, and Anomaly—designed to move email security beyond legacy signature-based systems. It allows organizations to analyze the sophisticated behavioral patterns of AI-driven threats rather than just searching for known malicious indicators.
Q2: How does the "Intent" dimension catch prompt injection?
Intent-based detection analyzes the "why" behind a communication. By identifying the underlying psychological manipulation and tactics used by an attacker, this approach can detect "Zero-Day" social engineering and phishing attempts that appear technically legitimate to traditional filters.
Q3: What role does "Deception" play in the HIDA framework?
Deception focuses on structural honesty. It analyzes the gap between what the human reader sees and what the machine parses, catching techniques like zero-font text or white-on-white CSS used to hide malicious AI directives.
Q4: Why is "Anomaly" detection better than sender reputation scores?
Reputation scores often miss compromised trusted accounts. Anomaly detection uses behavioral context to flag content that has no precedent in a sender's history—such as a regular vendor suddenly embedding hidden AI directives in an email.
Q5: How do the "5 D’s" solve the GenAI innovation-security gap?
The 5 D’s—Discover, Define, Defend, Discern, and Disclose—provide a roadmap for secure AI adoption. This structured methodology allows organizations to enable productivity while maintaining visibility and technical guardrails over LLM interactions.
Q6: Should organizations ban Generative AI to stay secure?
No. Outright bans usually lead to unmanaged, "Shadow" adoption. A proactive approach using the 5 D's methodology allows enterprises to embrace AI innovation while implementing the necessary governance to prevent data leakage and malicious prompt injections.
References
1. Permiso Security, "CO-PILOT, DISENGAGE AUTOPHISH," March 2026. CVE-2026-26133.
2. 0din / Mozilla, "Phishing For Gemini," July 2025.
3. OWASP, "LLM01:2025 Prompt Injection," Top 10 for LLM Applications 2025.
4. Sutton, M. and Ruck, D., "Indirect Prompt Injection: Generative AI's Greatest Security Flaw," CETaS, The Alan Turing Institute, November 2024.
5. CrowdStrike, "Prompt Injection: Definition and Attack Taxonomy," March 2026.
6. OWASP, "LLM Prompt Injection Prevention Cheat Sheet."
7. Google Workspace, "How Google Workspace with Gemini helps protect users from malicious content and prompt injection."
8. NIST AI Risk Management Framework, Generative AI Profile.
9. Aim Security / Aim Labs, "EchoLeak: Zero-Click AI Vulnerability in Microsoft 365 Copilot," June 2025. CVE-2025-32711. SOC Prime analysis: https://socprime.com/blog/cve-2025-32711-zero-click-ai-vulnerability/
Subscribe to Our Newsletters!
Be the first to get exclusive offers and the latest news



Tomorrow's Threats. Stopped Today.




